敏感词检测算法 - DFA
之前在系统中开发过一个敏感词检测的功能,最开始我很快完成了功能的设计开发:
- 敏感词库:存储所有敏感词的数据库表;
- 校验:查出所有敏感词集合,在循环中使用
String.contains()方法在目标串中进行敏感词查找,找到后抛出异常提示; - 预加载:敏感词集合不用每次都查数据库,可以提前加载缓存到内存,数据量也并不大。
但是使用暴力匹配算法未免简陋了点,于是便上网查找了下,果然还有更优的解决方案。这里我们先分析下String类的contains方法,即indexOf()方法的实现。
BF算法
BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。 -- 百度百科
直接看indexOf()方法的源码:
/**
* source:来源串(输入的文本),target:模式串(敏感词).
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
// 取敏感词的第一个字符
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
// 从输入文本中找到匹配敏感词第一个字符的字符
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
// 匹配到了第一个字符,继续向后匹配
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end &&
// 输入文本中的下一个字符是否与敏感词中的第二个字符相等,是则继续匹配
// 否则终止匹配,从文本的下一个字符开始重新匹配
source[j] == target[k]; j++, k++);
// j == end 说明上面这个循环走完了,即文本中完整的匹配到了敏感词,返回匹配的第一个字符处的index,代表成功
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}记source的长度为N,target的长度为M,该算法在最坏的情况下,单个敏感词匹配需要的比较次数为M * (N - M + 1),表示target在source的最后一段才匹配到,即时间复杂度为O(M * N),而要检测整个敏感词库(词库总数记为S)复杂度就变为O(S * M * N),效率太低。
DFA
具体实现源码主要参考了这篇文章:https://houbb.github.io/2020/01/07/sensitive-word-dfa
DFA 即 Deterministic Finite Automaton,就是确定有穷自动机。百科的描述比较抽象,主要是借助一张图来看:
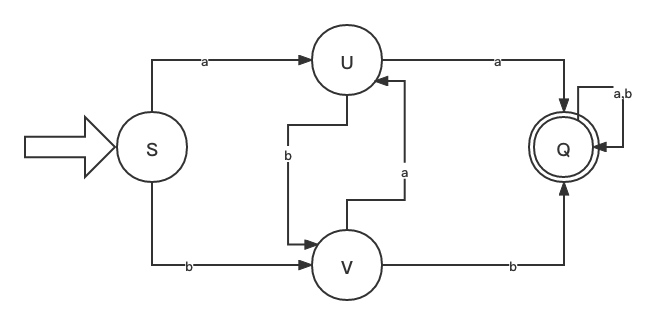
大写字母是状态,小写字母是动作,初始状态是S,终止状态是Q。通过状态 + 动作可以实现各种状态的转换,如下表:
| 状态 | a | b |
|---|---|---|
| S | U | V |
| U | Q | V |
| V | U | Q |
| Q | Q | Q |
而实现敏感词检测的关键就在于将敏感词构建成一个这样的状态图,通常是利用Trie字典树来实现。如下图:
利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
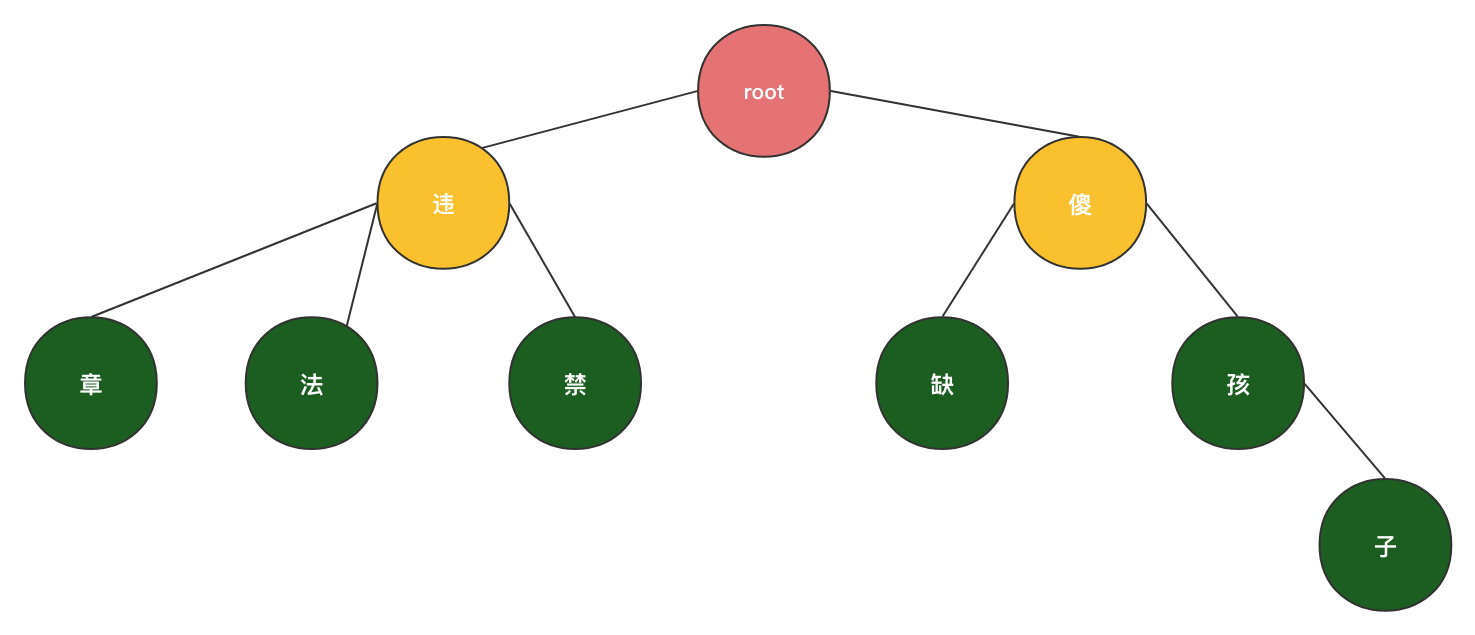
将敏感词库中的词构建成一棵棵字典树,每个节点即表示敏感词中的一个字符,那么从输入文本的第一个字符开始在Trie树上查找,即可实现敏感词的检测。Java中的实现我查了下基本都是利用HashMap来做的,构建完成后呈如下结构:
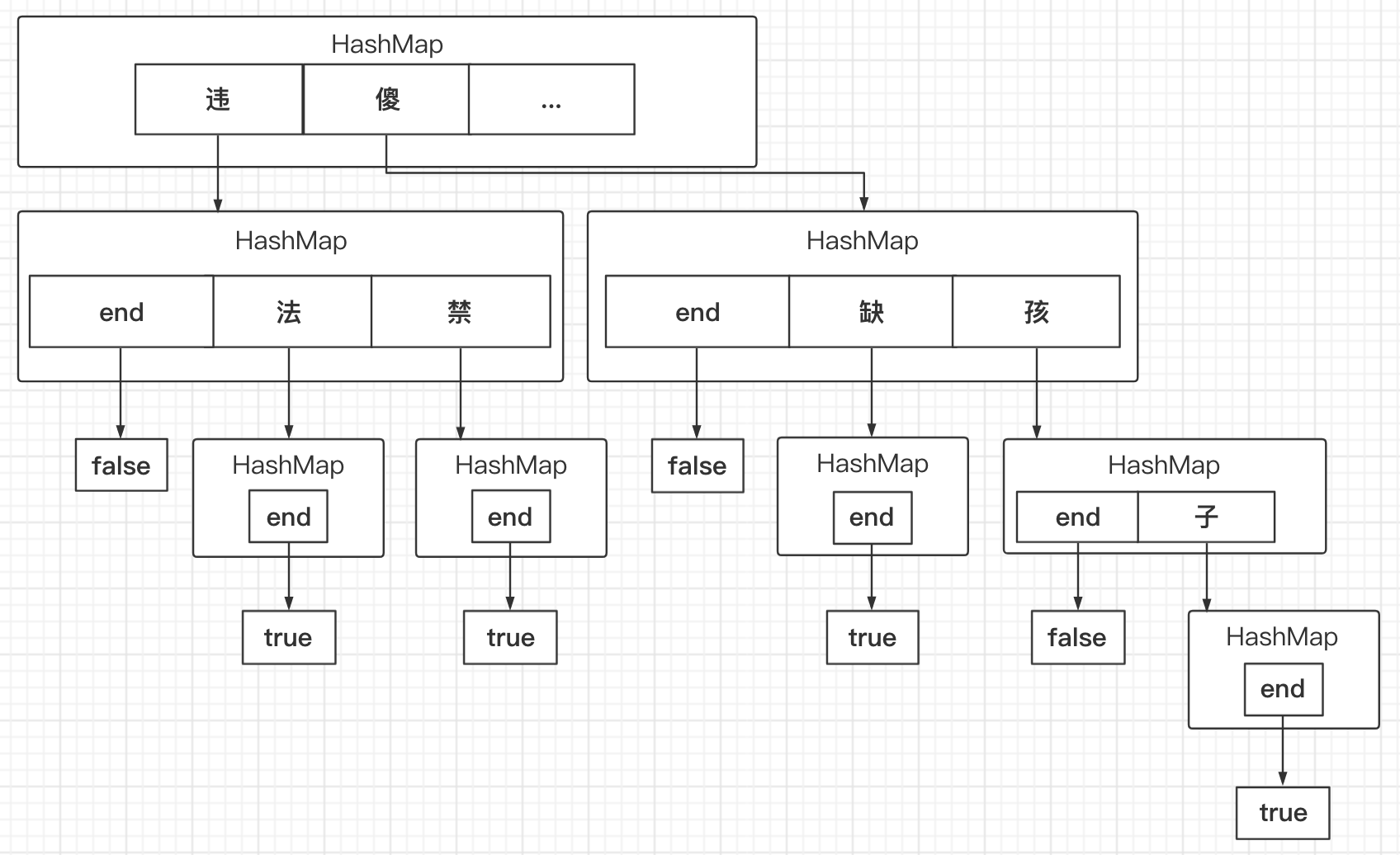
这样就把整个敏感词库构建出来了,只需要遍历一次输入的文本,就可以匹配出所有的敏感词,复杂度为O(N * M),效率相对高了许多。当然,这是以空间换来的,不过现在的服务器资源都比较充足,大部分系统敏感词库的大小也不会太大,是可以接受的。
小结
Trie树除了Hash结构的实现,还有其它数据结构的实现,有待研究。
双数组Trie树:https://www.cnblogs.com/en-heng/p/6265256.html。
目前只是利用DFA的思想实现了最简单基础的敏感词匹配,如果还涉及到组合敏感词、拼音敏感词等等,那就需要更复杂的算法来实现,最近刚好看到一篇文章,先记录下来。
vivo敏感词匹配系统的设计与实现:https://mp.weixin.qq.com/s/ZPqwK5wYg09vsGrluRmNZA
除了实现字符串匹配外,DFA也用于一些其它的场景。还有就是与之相反的NFA - 不确定的有穷自动机,也可以了解学习一下。